We Are the Unpaid Interns of the Data Age

Envision each online action you undertake, imprinting a permanent mark on the vast landscape of the internet. Every social media interaction, search query, and click you perform forms a distinctive digital narrative, carefully archived within the expansive data repositories of major tech corporations. In an age where controversies like the Cambridge Analytica scandal and subsequent documentaries have brought the opaque practices of data usage by major companies into public view, there remains a lesser-known facet of this digital dynamic we need to examine.
We appear to have grown comfortable with this complex digital dance, captivated by Spotify's remarkably accurate song recommendations, or Instagram's surprising knack for suggesting your next favorite skincare product just when you're considering a purchase. However, beneath the glossy veneer of these hyper-personalised experiences, there lies a critical aspect that we frequently disregard. Our time and cognitive energy, subtly harvested by these data-guzzling platforms, constitute a form of labor. What's more, this is labor for which we are not compensated. In essence, we find ourselves playing the role of unpaid interns in the data age, ceaselessly contributing valuable information without receiving any tangible rewards.
The Evolution of Data Collection
The concept of data collection is not a recent phenomenon. It is grounded in conventional sectors such as market research and healthcare, where instruments like surveys, customer feedback, and patient records have long been used as critical means to gather insights and drive decision-making processes. However, the advent of the internet and the subsequent digital revolution have resulted in an exponential increase in the breadth, volume, and diversity of collectable data, thus ushering in a new era in the sphere of data collection.
At present, titanic tech corporations have a distinct advantage, being the stewards of data from billions of global users who interact with their platforms daily. Each user action, whether it's clicking a link, sharing a post, liking a picture, or tagging a friend, is transformed into a precious piece of data. In return for this data, users are given access to a wide range of services, usually for free or at heavily subsidized rates. But the hidden cost of this arrangement is often ignored. Unknowingly, users perform unpaid labor, with their everyday online interactions contributing to the gargantuan profits reaped by these tech behemoths.
Decoding Google's reCAPTCHA
An illustrative case of this hidden labor is Google's reCAPTCHA system, which is encountered by most internet users as a ubiquitous element. This feature compels users to identify specific images from a selection, claiming it as part of the 'Completely Automated Public Turing test to tell Computers and Humans Apart' (CAPTCHA). Its primary purpose is to distinguish human users from bots, thereby safeguarding platforms from automated attacks.
However, keen observers may notice that the images usually portray everyday objects such as traffic lights, bicycles, and crosswalks. These selections are not arbitrarily chosen but instead serve a strategic purpose. This leads us to question: do these seemingly straightforward user interactions serve a dual purpose?
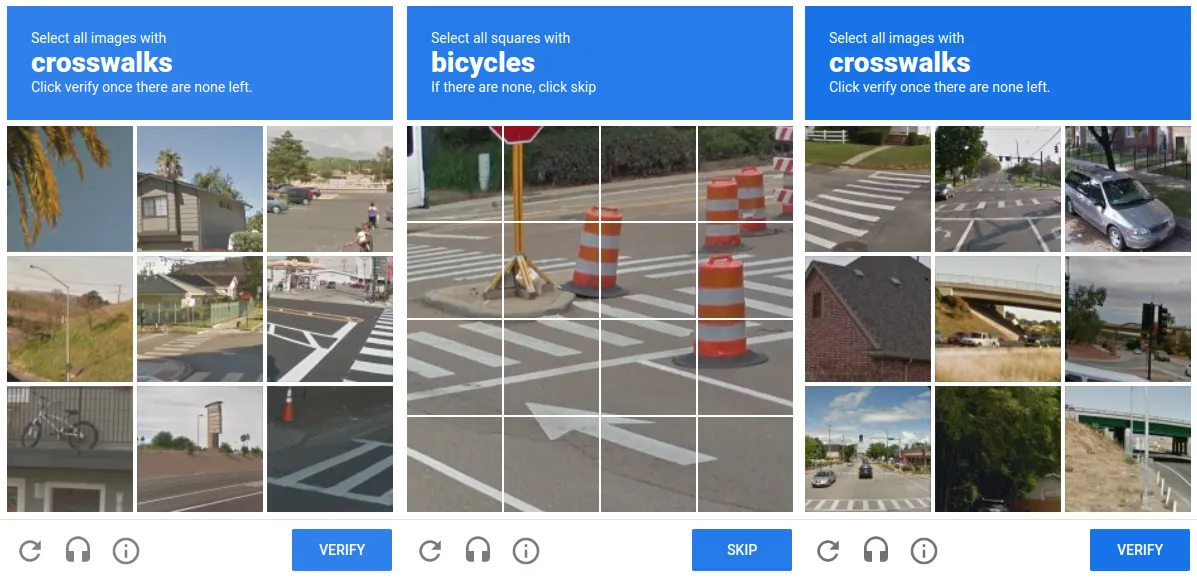
Contributing to Machine Learning: The Unseen Help
To shed light on this, let's consider Waymo, an Alphabet Inc. subsidiary that is actively involved in developing self-driving cars. Given the connection between Google and Waymo as part of the same parent company, it is plausible to speculate that our interactions with the reCAPTCHA system may unintentionally contribute to the development of Waymo's self-driving technology.
This speculation is not baseless. To delve deeper into the potential connection between Google's reCAPTCHA system and Waymo's self-driving technology, it is essential to understand the role of machine learning algorithms and the significance of labeled data in autonomous vehicle development. Numerous studies have emphasized the critical reliance of machine learning algorithms on vast amounts of labeled data to achieve accurate and efficient autonomous driving systems.
Research conducted by Felbo et al. (2015) underscores the importance of labeled data in training machine learning models for various applications, including autonomous vehicles. The study demonstrates that deep learning techniques can predict demographic information from mobile phone metadata. This highlights the pivotal role of labeled data in enabling algorithms to recognize patterns and make accurate predictions based on the given inputs.
Furthermore, this survey by Glanois et al., emphasizes the indispensable role of machine learning algorithms in autonomous driving. The study highlights that these algorithms heavily rely on extensive labeled data to understand complex traffic scenarios, make informed decisions, and ensure the safety of passengers and other road users. The accuracy and reliability of these algorithms are intricately linked to the quality and diversity of the labeled data used for training.
While concrete evidence directly linking reCAPTCHA interactions to Waymo's data collection practices might not be readily available, the existing knowledge on the significance of labeled data for machine learning algorithms in autonomous driving provides a strong foundation for this hypothesis.
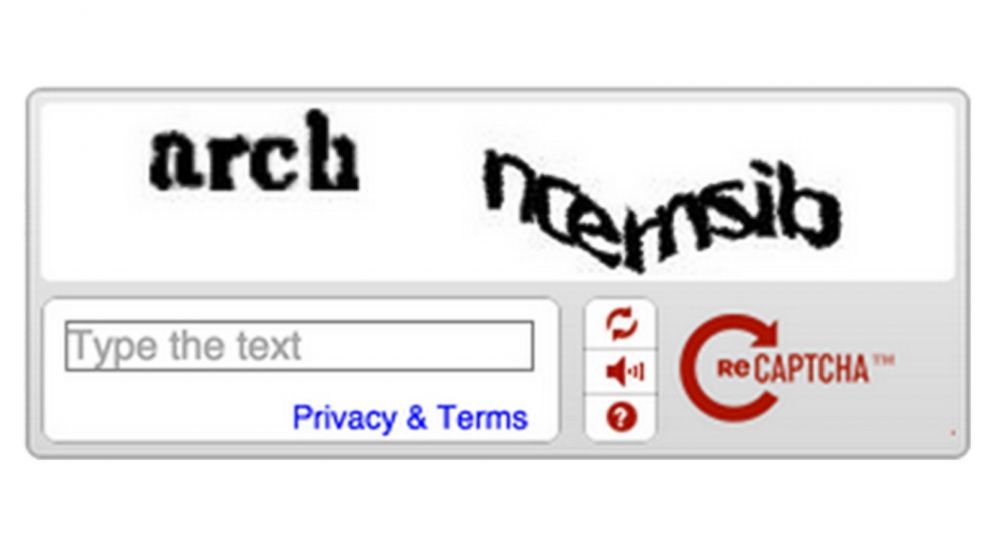
"Wait...what does it says?!
Google's data collection methodologies are a complex network of techniques that stretch beyond just collecting images of traffic signs or house numbers. As an example, consider the often-distorted series of letters and numbers you've probably been asked to decipher when verifying your identity online. These are not randomly generated character strings, as some might think. Instead, they are carefully selected snippets from an enormous library of print material that is in the queue to be digitized.
The digitization of printed material is a colossal task that encompasses the scanning of millions of pages and their subsequent conversion from image-based text to machine-readable format through a process known as Optical Character Recognition (OCR). OCR uses machine learning and artificial intelligence to recognize characters within an image and convert them into text that computers can manipulate and understand.
However, this process is far from flawless. OCR often results in errors due to complexities in human handwriting, variations in fonts, and quality of the scanned images. To minimize these errors and improve accuracy, the collected data needs to be checked and corrected – a step known as OCR error correction. And this is where your efforts in deciphering those scrambled characters come into play.
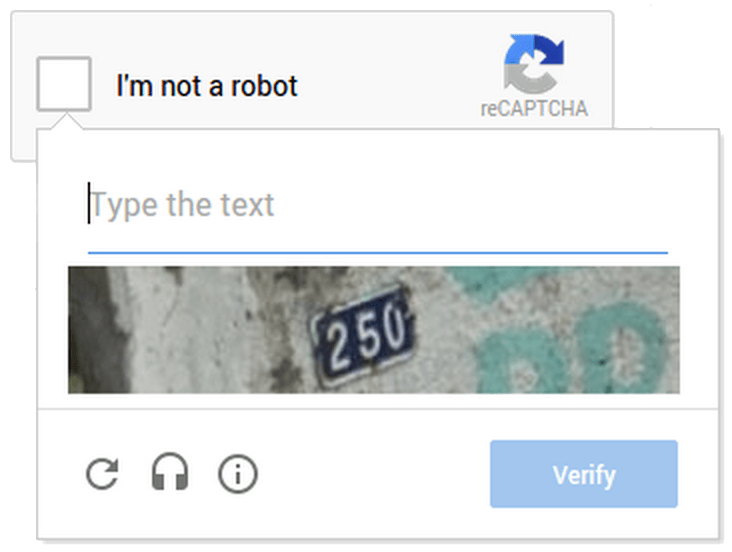
When you encounter one of these distorted character strings online, commonly known as CAPTCHAs, and successfully decode it, you are not only verifying your identity but also contributing to Google's massive effort to increase its OCR accuracy. Unbeknownst to you, you are effectively validating and rectifying OCR readings. Each validation and correction fine-tunes the system's recognition capabilities, reducing the chance of future mistakes.
In isolation, this action may seem minuscule or even trivial. However, when considering the sheer scale at which Google operates, it becomes evident that these accumulated 'free' corrections represent a significant value. A study published in 2013 estimated that about 300 million CAPTCHAs were solved daily by internet users worldwide. Given that each solution takes about 10 seconds on average, humanity collectively spends over 500,000 hours daily on this task, all of which contributes to Google's OCR refinement.
While this method of crowdsourcing corrections is a genius stroke in terms of saving time and resources, it does raise ethical questions. For one, the users providing these corrections are typically not aware that they are contributing to Google's massive data processing endeavors. It is an ingenious system, where a security measure doubles up as a means of improving Google's ability to digitize the world's printed information more accurately, fueling its dominance in the realm of information technology.

Beyond Google: Other Tech Giants' Subtle Strategies for Data Harvesting
Let's not single out Google here. Other technology giants have their own unique methods of accumulating and refining data to enhance their algorithms. They ingeniously blend these techniques into their services, prompting user interactions that provide valuable data, often without the user's explicit knowledge.

Consider social media platforms like Instagram and Facebook, which subtly stimulate our social instincts. One strategy they employ involves the "tag suggestions" feature, which prompts users to tag friends in the photos they upload. While this feature appears to be a simple tool designed to foster social interaction, in reality, it serves a dual purpose. Each tag that is added aids in the refinement of the platforms' facial recognition algorithms.
As outlined by Adrian Chen in 2014, these platforms take advantage of vast amounts of user-tagged images to train their AI models to recognize faces with extraordinary precision. Every tag enriches the social data available to these platforms, thereby enhancing the capabilities of their AI-powered facial recognition algorithms.
Another masterstroke in subtle data collection comes from Amazon, through its product review system. Ostensibly, the system's goal is to assist customers in making informed purchases based on other users' experiences. However, these user-generated reviews and ratings are instrumental in training Amazon's recommendation algorithms, as noted by Jannach and Adomavicius in 2016. Consequently, every review and rating you submit fuels Amazon's recommendation engine, transforming your consumer insights into valuable data that further refines their services.

Duolingo, a popular language-learning application, also employs an ingenious data collection strategy. By integrating translation tasks into its teaching methods, Duolingo amasses a massive database of multilingual data. According to a study by Tiedemann in 2012, this kind of data can significantly improve machine translation models. As users navigate through the language lessons and undertake translation exercises, they unknowingly contribute to the refinement of these models, providing a practical example of how learning can be intertwined with data collection.

Rethinking Data Collection Practices
The ethical considerations surrounding these data collection practices are increasingly coming under scrutiny. An abundance of users remain in the dark about the true value of the data they provide, not fully comprehending the extent to which it is exploited for profit maximization. While tech giants may assert that such data collection techniques significantly enhance user experience, it becomes evident upon examination that the primary beneficiaries are the corporations themselves.
Addressing this intricate issue requires an elevated level of transparency from companies regarding the usage and value of user data. In addition, there should be established policies that ensure users receive fair compensation for their contributions to these data repositories.
Achieving a more equitable landscape requires an exploration of alternatives to the current practices of data collection. Blockchain technology, with its potential for decentralization and enhanced security, emerges as a promising solution. It could potentially offer users direct control over their data and even provide compensation for sharing it. Another compelling proposition is the establishment of data cooperatives, where users would have collective ownership and management over their data.
These solutions, although fraught with their own unique challenges, signify a growing consensus among experts and the general public that the current status quo is untenable. As we move forward in this digital age, there must be an increasing emphasis on equitable data practices. Such practices should respect the contributions of users and the value they generate, rather than exploiting them for corporate gain.
Our seemingly innocuous online interactions, ranging from decoding reCAPTCHA images to writing product reviews, often have underlying motives that extend beyond their surface purpose. As users in this digital landscape, it's imperative that we critically examine and question the dynamics that exist between us and the tech conglomerates. We ought to demand transparency and endeavor to comprehend the real implications of our seemingly minor online contributions. After all, in this increasingly data-driven world, the old adage holds true – there's no such thing as a 'free' lunch.
In conclusion, as we navigate our increasingly interconnected digital lives, it becomes all the more crucial to remember the value of our own data. It's important that we understand how this data is used and to what extent it contributes to the success of big tech firms. Ultimately, the power should and must reside with us – the users. It's our data and we should have control over its usage, value, and compensation. This not only calls for a shift in the way these tech companies operate but also necessitates a stronger and more informed user base who can make demands and effect change. After all, our collective digital footprint shapes the online world – it's time we took ownership of it.
.
